使用分布式锁目的
对于分布式锁的目的,Martin 总结了两点
- Efficiency(效率) 在分布式系统中,避免不同节点重复做相同的工作,节约计算机资源。
- Correctness(正确) 避免不同节点并发处理同一段数据时,相互干扰结果。
Redlock设计
【思路】对某个资源加锁:在redis 添加resource_key;对某个资源解锁:从redis删除resource_key。检查锁是否被占用:resource_key是否已在redis创建;为了防止客户端崩溃或其他原因无法释放锁,要对锁设置TTL(Time To Live)。单例的分布式锁不可靠,需要n个master Redis服务器集群,获取大部分 Redis节点 的锁才算加锁成功。
主从模式的集群在master崩溃并不及时同步加锁信息给slave节点,slave有被升级为master时,可能会出现锁被获取多次,所以Redlock不使用。
简单实现
加锁
|
|
解锁
|
|
【问题:误解锁】clientA 获取锁,因为某种原因超时处理,如垃圾回收STW(Stop The World),锁到期自动释放。clientB获取锁,接着处理事件。clientA处理完事件后,释放锁脚本,这时将clientB加的锁释放掉。
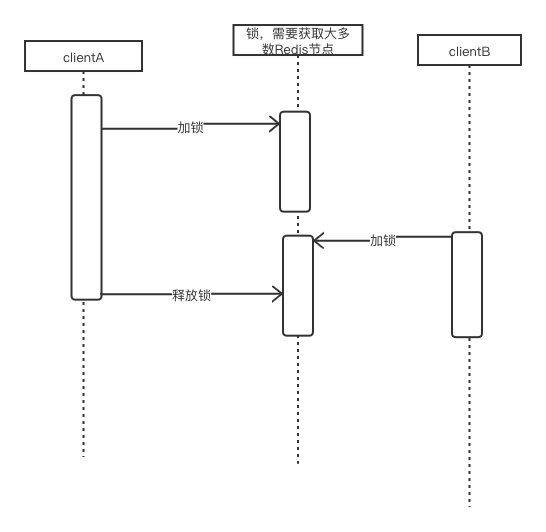
【解决】clientA加锁时,给resource_key 一个独一无二的值,如uuid,在解锁时,检查是否为自己加的锁。为了原子操作,使用lua脚本实现解锁
|
|
优化—–两个客户端同时获得锁问题
问题:clientA还没执行完事件并释放锁,就因为到期锁自动释放,且被clientB 获得,此时clientA和clientB同时对资源加锁
【解决】使用守护线程,在clientA没有执行完操作但锁快要过期时,延迟锁过期时间。当然守护线程也可能没能及时延长锁过期时间,只是减少此类事情的发生概率。
优化—- 由于网络延迟等原因,待客户端获得锁后,但锁已过期
问题:clientA 可能因为网络延迟,获得过期的锁
【解决】加锁成功后,再计算锁是否已过期,若过期,则重新申请加锁。
|
|
优化—–各个Redis节点的时钟存不一致
问题:因为Redis不同的节点的是时钟可能不同,锁过期不一致。
【解决】客户端计算锁是否过期时,将Redis节点之间的时钟偏差考虑进去,比如各个节点的偏移为 0.01 ms(和精确度有点相似),
我们设置偏移因子 clockDriftFactor=0.01 ,计算锁的有效期时,考虑便宜时间
|
|
若 validity<=0,则锁已过期
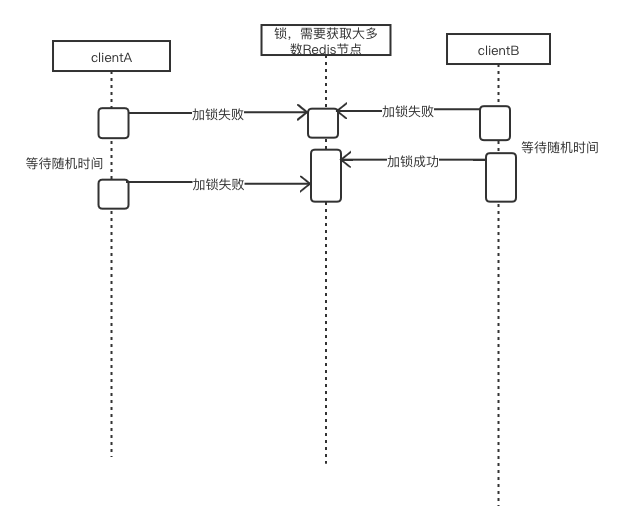
优化 —- 多个客户端同时申请锁,导致失败率升高
问题:多个客户端不断的尝试获取锁,会导致加锁成功率降低,严重可接近死锁。
【解决】当客户端尝试获取锁失败后,等待随机时间,再尝试
总结
Redlock锁不能保证绝对安全,它需要加锁的时间可预测的,Redis节点的时钟偏差是可预测的,才能降低冲突概率。